Kubernetes入門3: Podに割り当てるCPU時間を制限する
Kubernetesでは、VMを管理するとき同様に、Podに割り当てるリソースを制限することができます。
前回の記事のメモリの時と同様に、公式ドキュメントを参照しながら、Podに割り当てるCPU時間を制限する方法と挙動について試してみました。
- Podが制限以上のCPU時間を消費
- Podがノードに搭載されているCPU時間を要求する
の2パターンを試して、実際にどのような挙動となるか見ていきます。
準備
メモリの時と同じように、metrics-serverというadd-onsを有効にします。
$ minikube addons enable metrics-server
metrics-serverが実行されているかどうかは次のコマンドで確認できます。
$ kubectl get apiservices NAME v1beta1.metrics.k8s.io
今回のチュートリアル用にnamespaceを作成します。
$ kubectl create namespace cpu-example namespace/cpu-example created $ kubectl get namespaces NAME STATUS AGE cpu-example Active 18s
Podが要求通りのCPU時間を消費
Podを構成するコンテナのCPU要求を0.5cpu、CPU制限を1cpuとして設定します。また、2cpuを消費するコンテナを実行しています。
# https://k8s.io/examples/pods/resource/cpu-request-limit.yaml apiVersion: v1 kind: Pod metadata: name: cpu-demo namespace: cpu-example spec: containers: - name: cpu-demo-ctr image: vish/stress resources: limits: cpu: "1" requests: cpu: "0.5" args: - -cpus - "2"
Podを作成。
$ kubectl create -f https://k8s.io/examples/pods/resource/cpu-request-limit.yaml --namespace=cpu-example
作成したPodが使用中のCPU時間を表示。
$ kubectl top pods cpu-demo --namespace=cpu-example NAME CPU(cores) MEMORY(bytes) cpu-demo 998m 1Mi
Podはstressコマンドによって、2CPUを消費しようとしていますが、制限値を超えて利用することはできないことがわかります。
Podを削除。
$ kubectl delete pods cpu-demo --namespace=cpu-example
Podがノードに搭載されているCPU時間を要求する
最後に膨大なCPU(設定では100cpu)を要求した時の挙動を見ていきます。
# https://k8s.io/examples/pods/resource/cpu-request-limit-2.yaml apiVersion: v1 kind: Pod metadata: name: cpu-demo-2 namespace: cpu-example spec: containers: - name: cpu-demo-ctr-2 image: vish/stress resources: limits: cpu: "100" requests: cpu: "100" args: - -cpus - "2"
Podの作成
$ kubectl create -f https://k8s.io/examples/pods/resource/cpu-request-limit-2.yaml --namespace=cpu-example
Podの情報を取得すると、STATUSが、 Pending となっています。つまり、Podはスケジューリングされておらず、どのノードでも動作していない状態となります。
$ kubectl get pod cpu-demo-2 --namespace=cpu-example
Podの詳細情報を表示すると、
$ kubectl describe pod cpu-demo-2 --namespace=cpu-example
次のように、ノード上のCPU不足により、スケジューリングができないことがわかります。
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 32s (x7 over 1m) default-scheduler 0/1 nodes are available: 1 Insufficient cpu.
PodとNamespaceを削除して終了。
$ kubectl delete pod cpu-demo-2 --namespace=cpu-example $ kubectl delete namespaces cpu-example
以上で、CPU時間割り当てに関するチュートリアルは終了となります。Kubernetesで管理できるリソースはCPUやメモリ以外にもボリュームなどさまざまなものがあり、VMと同じようにリソース管理するための機能が備わっています。次は、拡張リソースやボリュームなど、管理するには難易度が少し高いリソースについてまとめていきたいと思います。
Kubernetes入門2: Podに割り当てるメモリを制限する
Kubernetesでは、VMを管理するとき同様に、Podに割り当てるリソースを制限することができます。公式ドキュメントを参照しながら、Podに割り当てるメモリを制限する方法と挙動について試してみました。英語が得意な方は元記事をご参照ください。
- Podが制限以下のメモリを消費
- Podが制限以上のメモリを消費
- Podがノードに搭載されているリソース以上のメモリを要求する
の3パターンを試して、実際にどのような挙動となるか見ていきます。
準備
metrics-serverというadd-onsを有効にします。
$ minikube addons enable metrics-server
metrics-serverが実行されているかどうかは次のコマンドで確認できます。
$ kubectl get apiservices NAME v1beta1.metrics.k8s.io
今回のチュートリアル用にnamespaceを作成します。
$ kubectl create namespace mem-example namespace/mem-example created $ kubectl get namespaces NAME STATUS AGE mem-example Active 18s
Podが制限以下のメモリを消費
まず、Podが要求するメモリ量とKubernetesによって制限されるメモリ量を設定ファイルに定義します。 Podが要求するメモリを100MiB、制限を200MiBとし、150MiB程度のメモリを消費するコンテナを定義しています。
# https://k8s.io/examples/pods/resource/memory-request-limit.yaml apiVersion: v1 kind: Pod metadata: name: memory-demo namespace: mem-example spec: containers: - name: memory-demo-ctr image: polinux/stress resources: limits: memory: "200Mi" requests: memory: "100Mi" command: ["stress"] args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
Podを作成。
$ kubectl create -f https://k8s.io/examples/pods/resource/memory-request-limit.yaml --namespace=mem-example
作成したPodが利用中のメモリ量を出力。
$ kubectl top pod --namespace=mem-example NAME CPU(cores) MEMORY(bytes) memory-demo 61m 150Mi
Podが実際に利用してるメモリ(150MiB)が、要求したメモリ(100MiB)よりも大きな値となっていますが、制限値である200MiBよりも小さな値ですので、Podは問題なく動作しています。
Podを削除。
$ kubectl delete pods memory-demo --namespace=mem-example
Podが制限以上のメモリを消費
次に制限値以上のメモリを消費した場合の挙動を見ていきます。設定ファイルは以下の通りです。制限値100MiBに対し、250MiBのメモリを消費するコンテナを起動するように定義しています。
# https://k8s.io/examples/pods/resource/memory-request-limit-2.yaml apiVersion: v1 kind: Pod metadata: name: memory-demo-2 namespace: mem-example spec: containers: - name: memory-demo-2-ctr image: polinux/stress resources: requests: memory: "50Mi" limits: memory: "100Mi" command: ["stress"] args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
Podを作成。
$ kubectl create -f https://k8s.io/examples/pods/resource/memory-request-limit-2.yaml --namespace=mem-example
Pod状態を取得すると、STATUSが OOMKilled となっており、メモリ不足により、プロセスがkillされたことがわかります。
$ kubectl get pods --namespace=mem-example NAME READY STATUS RESTARTS AGE memory-demo-2 0/1 OOMKilled 1 10s
このPodは、強制終了されても、再起動を試みていますので、再度情報を取得してみると、STATUSが CrashLoopBackOff となっていることがわかります。
$ kubectl get pods --namespace=mem-example NAME READY STATUS RESTARTS AGE memory-demo-2 0/1 CrashLoopBackOff 3 1m
Podを削除。
$ kubectl delete pods memory-demo-2 --namespace=mem-example
Podがノードに搭載されているリソース以上のメモリを要求する
最後に、膨大なメモリ(設定では1000GiB)を要求するPodを作成した場合にどのような挙動を示すのか見てみます。
# https://k8s.io/examples/pods/resource/memory-request-limit-3.yaml apiVersion: v1 kind: Pod metadata: name: memory-demo-3 namespace: mem-example spec: containers: - name: memory-demo-3-ctr image: polinux/stress resources: limits: memory: "1000Gi" requests: memory: "1000Gi" command: ["stress"] args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
Podの作成
$ kubectl create -f https://k8s.io/examples/pods/resource/memory-request-limit-3.yaml --namespace=mem-example
Podの情報を取得すると、STATUSが、 Pending となっています。つまり、Podはスケジューリングされておらず、どのノードでも動作していない状態となります。
$ kubectl get pod memory-demo-3 --namespace=mem-example NAME READY STATUS RESTARTS AGE memory-demo-3 0/1 Pending 0 2m
Podの詳細情報を表示すると、
$ kubectl describe pod memory-demo-3 --namespace=mem-example
次のように、ノード上のメモリ不足により、スケジューリングができないことがわかります。
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 40s (x22 over 5m) default-scheduler 0/1 nodes are available: 1 Insufficient memory.
PodとNamespaceを削除して終了。
$ kubectl delete pod memory-demo-3 --namespace=mem-example $ kubectl delete namespaces mem-example
以上で、メモリ割り当てに関するチュートリアルは終了となります。次は、CPU割り当てについて試して見たいと思います。
Kubernetes入門1: Hello Minikube
Kubernetesは公式ドキュメントが充実しており、さまざまなチュートリアルも用意されています。今回はその中の一つである、Hello Minikubeを参考にチュートリアル記事を書いてみました。*1
Minikubeとは
いざKubernetesを試してみようと思った時に、たくさんサーバを用意することは出来ない、インストールが難しい、といった理由で断念してしまう人もいるかもしれません。*2
Minikubeは、MacやLinuxなど手元のマシンで簡単にKubernetesを試すことができるツールです。 例えば、Macでminikubeを試すと、Mac上に一台VMを立ち上げて、その中に自動的にKubernetesをインストールして、一台構成のKubernetesお試し環境が出来上がります。 ちょっとKubernetesを試して見たい人にはおすすめの環境ですのでぜひ利用してみてください。
インストール
ここでは、Macでのインストール方法を載せておきます。LinuxやWindowsでもワンライナーでインストール可能のようですので、ご自身の環境に合わせてインストールしてください。
$ brew cask install minikube
これで、インストール終了です。 他にも、Macで利用するためのkubectlなどのインストールが必要なのですが、詳細は Install Minikube - Kubernetes をご参照ください。
All-in-one VMの起動
起動も簡単で、virtualboxをインストールしてあるときは、以下のコマンドを実行します。
$ minikube --vm-driver=virtualbox start
// Virtualboxのコンソールや以下のコマンドでVMが出来てることを確認
$ VBoxManage list vms
"minikube" {xxx}
これでKurbernetesがインストール済のVMが作成され、起動しました。
Podを作成してから削除するまでの一連のコマンドを試す
Pod起動
Dockerチュートリアルでもよくみるnginxが含まれたPodを起動します。
$ kubectl run hello-node --image=nginx --port=80
Pod取得
$ kubectl get pods NAME READY STATUS RESTARTS AGE hello-node-79c9b49558-dtq8d 1/1 Running 0 54s
Service作成
KubernetesはPodを作成しただけでは、外部からそのPodにアクセスできませんので、Serviceを作成して外部からアクセス可能とします。
$ kubectl expose deployment hello-node --type=NodePort service/hello-node exposed
Serviceにアクセス
起動したコンテナには、minikube VMのIP:portでアクセスすることができます。
$ curl $(minikube service hello-node --url) ... // nginxのhtmlが返ってきます
ブラウザでアクセスするには、
$ minikube service hello-node --url
のコマンドでIPとPortを取得して、それをブラウザで開けばアクセスすることが可能です。
ServiceとPodの削除
$ kubectl delete services hello-node $ kubectl delete deployments hello-node
ダッシュボードの利用
$ minikube dashboard
ブラウザ経由でKubernetesクラスタの管理をすることができます。kubectlを利用して作成したPod情報なども見ることができ、直感的な理解の助けになるので、ぜひ試してみてください。
これで、チュートリアルその1は終了です。次回はこの環境を活用して、Kubernetesの他のチュートリアルなども試してみたいと思います。
*1:公式チュートリアルでは自分でDockerイメージを作成しており敷居が高ので、より簡略化しています。
*2:今はkubeadmなどで比較的容易にインストール可能ですが、初期のKubernetesは少し難しかったのです
Googleの新サービスCloud Service Platform。Istioなどを利用。
Googleの新サービス基盤 Cloud Service Platform について、Googleの公式ブログで発表されています。 Cloud Services Platformについては、Google Cloud Next '18でも発表されており、日本語の記事もいくつか出ています。 本サービスは、オンプレとクラウド上で動く全てのITシステムに対して、一貫性のあるフレームワークを提供することを目的としている。おそらく、オンプレにシステムを抱えているユーザに対し、クラウドへの緩やかな移行を促すことを目的としているのではないかと思われる。

本サービスの特徴として、
- Service mesh: マネージドなIstioの提供
- Hybrid Computing: GKE On-premによるオンプレとクラウドのマルチクラスタ管理
- Policy enforcement: Kubernetes workloadの制御を可能とするGKEポリシー管理
- Ops tooling: 監視を一元的に可能なStackdriver Service Monitoring
- Serverless computing: GKE Serverless add-onとKnative
- Developer tools: マネージドなCI/CD環境
などが挙げられます。本サービスを活用し、オンプレで稼働しているレガシーなアプリケーションのコンテナ化をすることで、即座にクラウドレディなマイクロサービスを開発することができると思われます。*1
ここ数日、Googleクラウド関連のサービスについて注目し記事にしていっている通り、Googleはオンプレに閉じているレガシーな顧客に対し、アプリケーションのコンテナ化とKubernetesの導入の敷居を下げるようなサービスを発表していっています。
今後、比較的レガシーな開発を実施することが多いSIerに対してもますますKubernetesなどの導入要望は強まっていくと思われますので、今後の業界動向について目を離すことはできない状況となっています。
*1:もちろんレガシーなアプリケーションをコンテナ化するという部分が即座にできるとは思えません。
KubernetesやIstio、Knativeに関するPodcastが公開されました
PodCTL #43 - “Istio, Knative and GoogleNEXT announcements”https://t.co/fdzsfSJFqH
— PodCTL (@PodCtl) 2018年7月28日
RedHatにより提供されているPodcastにて、v1.0の公開から3周年を迎えたKubernetes、Istio、Knative、およびGoogle Next '18のKubernetes関連の発表について議論されています。
GKE On-Premは、本ブログでも何度か記事にしましたが、Kubernetesをユーザのデータセンターなどのオンプレ環境で利用するためのサービスです。まずはアルファ版の提供からとなりますので、早く試してみたい方は早期利用リクエストを投げることをお薦めします。
Knativeは、Kubernetes上でサーバレスなワークロードを動かすための基本的なビルディングブロックを提供します。AWS Lambdaによりサーバレス自体は前々から注目されてきていますが、今後より一般的な概念になり利用ユーザも増えていくことが見込まれます。
Istioは、マイクロサービスにより構成されるサービスメッシュを管理するためのソフトウェアで、CNCFの一員として開発されているOSSです。GKEとも連携して使うことができるようになりました。
今後もしばらくはGoogle Cloud Next '18の発表内容を踏まえた議論が多くされていきそうで、ますますクラウド、Kubernetes、コンテナ界隈から目を離すことができません。 ITエンジニアとしては、動向をウォッチするだけでなく、自らOSSやサービスを利用して知見をためていく必要がありそうです。 本ブログは、動向をウォッチするためのポインタとなることを目指しつつ、月数回の頻度で詳細な解説記事を載せていく予定です。
GoogleによるクラウドイベントGoogle Cloud Next ‘18が盛況のうちに終了
GKE On-PremやKnativeなど、日本でもバズるような興味深い発表が多くあったGoogle Cloud Next ‘18が終了しました。 Keynoteによると、Google過去最大規模のイベントとなったそうで、25,000以上の参加登録があったようです。 日本語でもさまざまな記事が出ていますが、どんな発表があったのか、気になる方はrecap記事を是非参照してみてください。 www.blog.google
イベントの名前にもあるCloud関連については新サービス含め、機能強化などさまざまな発表がありました。
GKE On-Prem
techlunch.hatenablog.com 本イベントの目玉の一つですね。詳細は過去記事やその先のリンクをご参照ください。
Serverless containers, Knative
cloudplatform.googleblog.com こちらも目玉の一つで、日本語記事もたくさん書かれています。筆者は実はserverlessの使いどころが明確に見えておらず、現時点で利用したことがありませんし、引き合いもそこまで多くありませんでした。 しかし、今後話を聞かれることはますます多くなると思いますので、勉強して詳細な記事を書きたいと思っています。
Stackdriver Service Monitoring
GCPやAWSなどのクラウドで実行されるアプリケーションのパフォーマンスやアップタイムなどをグラフィカルに確認することができます。NginxやApacheなどよく利用されるアプリケーションに対応しており、さまざまな情報が取得することができます。 もちろんアラート機能も具備していますので、slackやメール通知など運用に役立てることが可能です。 独自のビジネスアプリケーションを監視するための設定も可能なようなので、幅広く利用ができそうです。
Cloud Functions
サーバレスプラットフォームであるCloud Functionの一般供用が開始されました。100ms単位に丸められて課金されるようですので、バッチ処理など常駐しないアプリケーションが多いユーザはコスト削減につながるかもしれません。
マネージドサービスの拡充
フルマネージドなサービスのラインナップが拡充されました。今まで、特定の製品に縛られて自分たちで運用せざるを得なかったユーザもどんどんとクラウドに移行していくことになるだろうと思われます。
その他にも、今流行りのAI関連やIoT、エッジ向けの話など幅広い話がありました。9月には東京でGoogle Cloud Next ’18 in Tokyo | 9 月 19 ~ 20 日、東京が開催される予定ですので、時間があるかたは是非参加して見てはいかがでしょうか。
KubernetesのCPU Managerの解説記事を見て勉強しよう
Kubernetesの公式ブログで、Feature Highlight: CPU Manager - Kubernetes という記事が上がっていました。デファクトのコンテナオーケストレーターであるKubernetesの概要を掴むチャンスですので、概説します。
Kubernetesアーキテクチャ
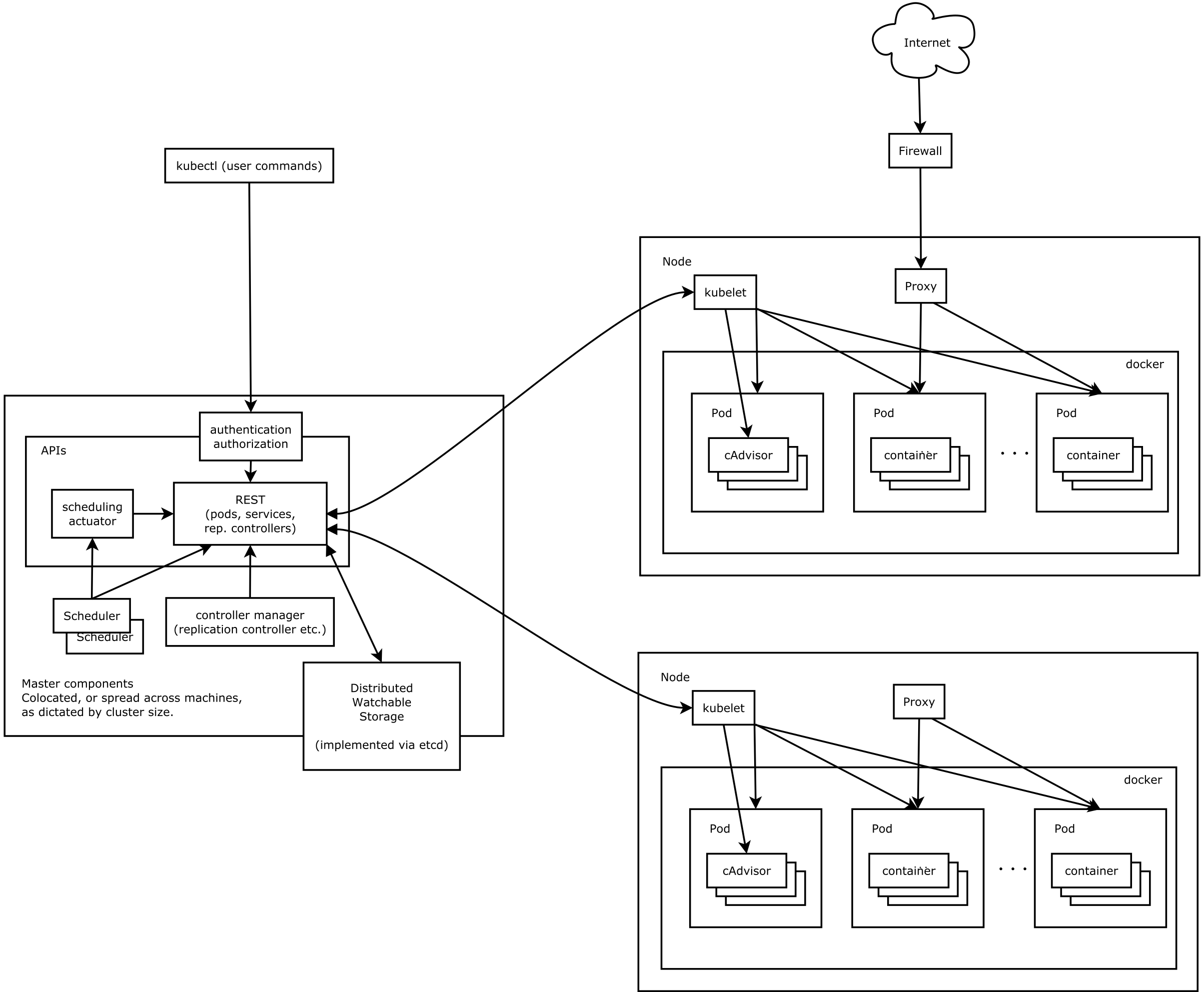
そもそもKubernetesはどのようなシステムで構成されているのか疑問に思っている方も多いかと思いますので、Githubに上がっていた図を貼り付けておきます。
CPU Managerは名前から類推されるとおり、controller managerと呼ばれるシステムコンポーネントの一機能となります。
controller managerは、Podのレプリカ数の管理など、コンテナ化されたアプリケーションが正常に動作するためのさまざまな制御機能を有しています。
CPU Manager
When CPU manager is enabled with the “static” policy, it manages a shared pool of CPUs. Initially this shared pool contains all the CPUs in the compute node. When a container with integer CPU request in a Guaranteed pod is created by the Kubelet, CPUs for that container are removed from the shared pool and assigned exclusively for the lifetime of the container. Other containers are migrated off these exclusively allocated CPUs.
簡単に言うと、特定のPodのみがCPUを排他的に利用すること可能となるようです。引用文を読む限り、排他的に割り当てられたCPUを他のPod(コンテナ)は利用することはできなくなるように見えます。
これにより、CPU-intensiveなワークロードは、CPU時間を有効活用することができるため、純粋な処理時間が増えるだけでなく、context switchやcache missによるオーバヘッドも削減することが可能となります。
CPU-intensiveなワークロードって何?と感じるかたもいるかもしれませんが、I/Oが少なく、計算が多く走るような処理のことです。
CPUの配分方法としては、CPU配分をワークロードごとに重み付けをする方法や、スケジューリング期間中にPodに割り当てる実時間を指定する方法などもありますが、CPUを排他的に利用することが可能になれば、複雑なスケジューリングも考える必要がなくなるため、有用な手段と言えるかと思います。
元記事には性能評価結果も載っているので興味ある方は参照ください。
まだbeta featuresのようですが、ワークロードの特性によっては一度試してみたい機能となります。